
Hello Tech Enthusiasts! Today We are going to be looking at an often-overlooked area of Artificial Intelligence (AI), The AI Unlearning Problem. We all are well aware of the power of AI. It is integrated so deeply into our daily lives that everything we do online has AI working behind the scenes one way or another. From Instagram reel suggestions, and ads to Chatbots like Siri or Alexa to Deepfakes, We are surrounded by an ocean of AI tools that are continuously learning about us, improving themselves to predict our behavior and move in the direction, their businesses want us to (Scary right?). But How do these AI tools learn about us?
There are plenty of blogs and resources online that answer this question and of course, the answer is through the data being collected about us by the same businesses. Our cameras, microphones, online browsing, what we like, what we order, even what we look at and how long we look at it (Yes, Incognito too), everything is being recorded by the biggest corporations to be fed to their AI algorithms and predict our future behavior. I know what you are thinking, These corporations ask for our permissions, often left unread terms and conditions, that allow them to collect this data, so we should not have a problem with this. But, What if we don’t want to share our data anymore? Since the data already collected about us is also owned by us, we should have a right to delete that data too, right? Let’s assume that companies honor our request and delete our data, AI tools being trained on that should also delete the data and change itself, right? But, What does it mean for AI to actually delete or ‘Un-learn’ that?

The concept of Unlearning in AI is a relatively new idea. It involves an AI disregarding the information previously learned, maybe because it is wrong, outdated, or just irrelevant, without affecting its core knowledge base. It also means removing or untraining a specific part of the dataset when it is no longer relevant. This is especially important when an AI may have learned biased or inaccurate information from a dataset. It’s a quality of humans to disregard, ignore, or just forget the data that is irrelevant to the current decision making but AI hasn’t been able to replicate this same quality yet.
Unlearning isn’t a mere programming glitch in AI. It’s a fundamental issue that makes it difficult to trust the reliability and fairness of AI systems. AI, at its base, emulates human cognition or intelligence and unlearning or forgetfulness is an important part of it which AI should mitigate as well. As an example, Unlearning would help AI adapt to new data and make better decisions according to recent environmental changes.
Unlearning as a technique has a great number of applications in the realm of AI systems. From Computer Vision to robotics to Autonomous driving technology to Deepfakes, Unlearning can help engineers create smarter AI models, that have a better understanding of their environment. They will be able to use the relevant past data, not all past data, to make better decisions in the future, therefore imitating human-like abilities. In other words, Unlearning can help machine learning models learn and adapt over time according to their surroundings to be better efficient at producing outputs without going through hours of re-training. But, isn’t it better to be aware of all past data to make better decisions? How does unlearning impact current AI applications?

While the above section discusses the impacts of AI’s ability to unlearn, let’s come back to the current reality, AI’s inability to unlearn.
AI’s inability to unlearn also poses significant risks and issues. One of the biggest concerns of this inability is biased decision-making. For example, if AI is trained on a dataset that does not properly represent the population at large, It will automatically learn and reinforce systematic biases. This will lead to decisions that have a disadvantage to the minority group, which doesn’t follow one of the main foundation principles of AI, being fair. Moreover, If AI cannot unlearn or forget irrelevant or outdated data, It will continue to provide information or make decisions that are inaccurate and since AI is a big part of the decision-making process of humans, It will lead to a chain of wrong interpretations, causing big damages. Thus, It is an important part of the future of AI to have the ability to forget things.
But, It isn’t easy to implement (Although, I said it so easily :)). Implementation of Unlearning poses a great challenge in the performance of AI systems. If AI unlearns vital pieces of information, it can lead to negative consequences as well like incorrect interpretation of data or wrong decisions. It might also unlearn the minority or less common data as outliers, increasing the biases in AI systems, and destroying the objective of fair AI systems. For example, In fraud detection systems, If AI unlearns key patterns of fraud, It can lead to more false positives, thereby reducing the AI systems’ overall accuracy and reliability.
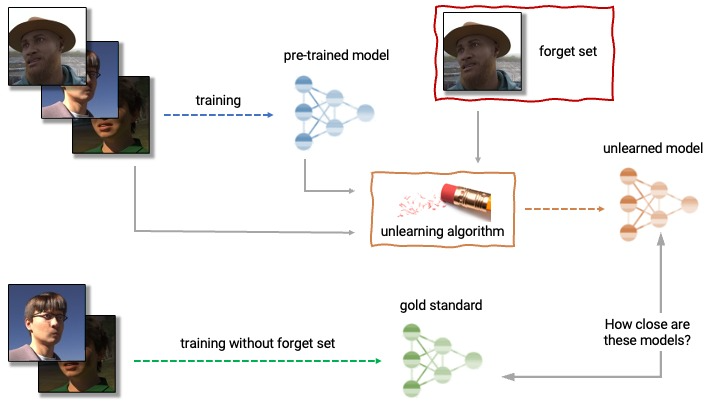
There have been several researches going on to address this unlearning problem. On one hand, Researchers are claiming it is virtually impossible to make an AI model forget or unlearn things. The main reason behind this is that when we delete data from AI algorithms, It may result in the system functioning improperly. AI learning means finding a statistical relationship between the data points in the dataset which is far too complex to be comprehended by humans. Therefore, It is nearly impossible for AI to ignore some portions of the data that it is already from. The only real way is to retrain the whole algorithm with deleted data, which is far too expensive on resources.
Thus, Unlearning requires a different way of recognizing patterns in data to leave room for adapting and improving when trained on new data like changing conditions in the environment. Several researches have been going on for these methods. Some of the promising methods are:
Finally, the AI Unlearning problem currently poses great challenges. It hinders the ability of Artificial Intelligence to mimic the human-like learning and unlearning process, blocking the way to bridge the gap to Artificial General Intelligence. The field of Continuous learning is still embryonic but the methodologies like LwF and Dynamic architecture show early promises of solving this problem. We must keep researching and pushing the boundaries of Artificial Intelligence as this will significantly enhance the current AI systems, opening the way to new possibilities and applications.
3 Comments
Explainable AI (XAI) : Making AI transparent | Dishu BansalSeptember 2, 2023
[…] productivity. As AI models continue to evolve and become increasingly complex, challenges like the AI Unlearning problem will need to be addressed, making XAI increasingly important as the business and end customers’ […]
tempmailkSeptember 2, 2023
This was beautiful Admin. Thank you for your reflections.
Tree MailSeptember 2, 2023
of course like your website but you have to check the spelling on several of your posts A number of them are rife with spelling issues and I in finding it very troublesome to inform the reality on the other hand I will certainly come back again